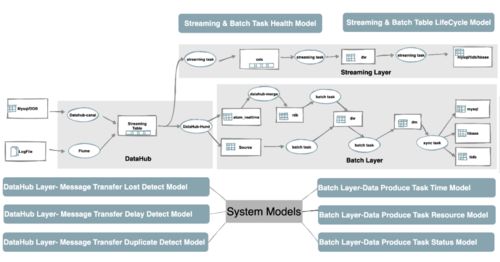
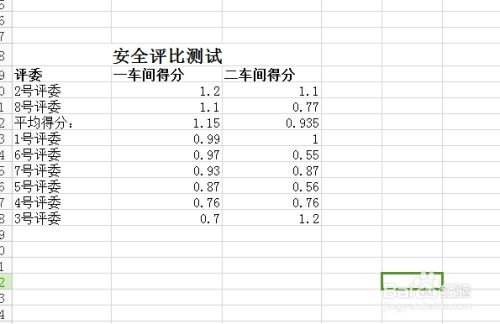
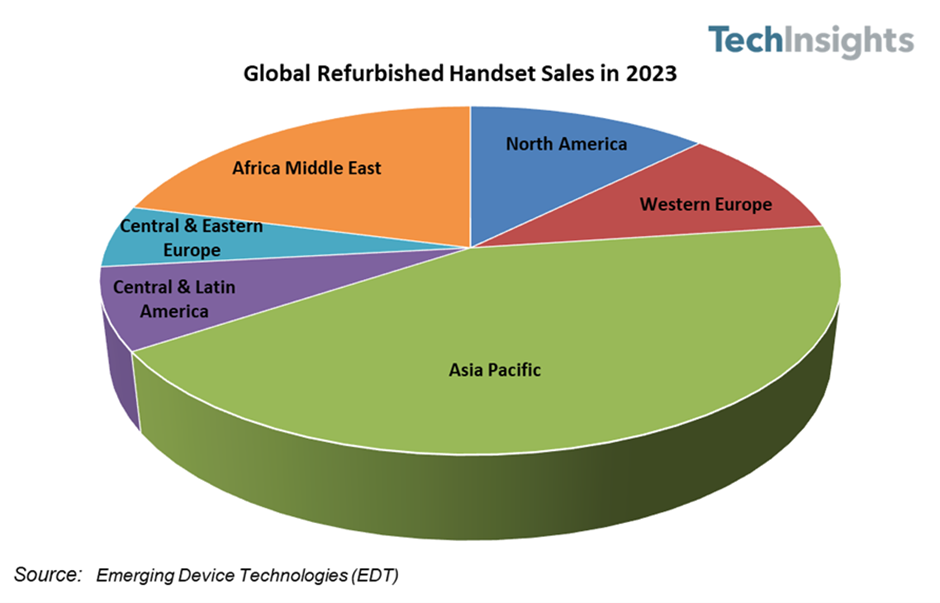
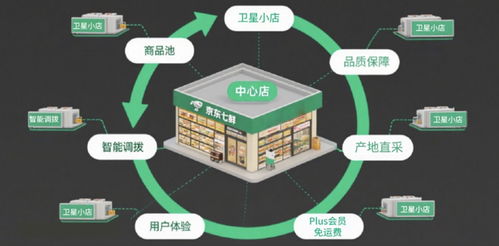
在數據驅動的時代,文本數據作為非結構化數據的主要形式,其規模正以前所未有的速度增長。從社交媒體評論、新聞資訊、學術文獻到企業日志、客服對話,文本大數據蘊含著巨大的價值。要有效挖掘這些價值,一個經過精心設計的、能夠提供強大存儲支持服務的底層架構至關重要。本文旨在探討文本大數據存儲支持服務的設計核心與關鍵考量。
一、設計核心:分層、彈性與智能化
文本大數據存儲支持服務的設計絕非簡單的磁盤陣列堆砌,而是一個融合了數據全生命周期管理的系統工程。其核心設計理念應圍繞以下三點展開:
- 分層存儲策略:根據文本數據的訪問頻率、價值密度和處理要求,將其劃分為熱數據、溫數據和冷數據。熱數據(如實時分析中的近期日志)需要部署在高性能的SSD或內存數據庫中,以保證毫秒級響應;溫數據(如過去數月的業務文檔)可存放在性能與成本均衡的分布式文件系統(如HDFS)或對象存儲中;冷數據(如合規性要求的多年存檔)則可遷移至成本極低的磁帶庫或冰川式對象存儲。智能的數據生命周期管理策略能自動完成數據在不同層級間的流動,實現成本與性能的最優平衡。
- 彈性可擴展架構:文本數據的增長是持續且難以精確預測的。因此,存儲架構必須具備水平擴展能力,能夠通過增加節點來近乎線性地提升存儲容量和吞吐量。云原生的對象存儲服務(如AWS S3、阿里云OSS)或自建的基于Ceph、MinIO的分布式存儲系統是理想選擇。它們不僅提供了近乎無限的擴展性,還天然支持多副本或糾刪碼機制,保障數據的高可用性和持久性。
- 智能化元數據與索引服務:海量文本的價值解鎖依賴于高效的檢索與分析。存儲系統需要提供強大的元數據管理能力,為每份文本數據打上豐富的標簽(如來源、生成時間、主題、情感傾向、關鍵實體等)。需要集成或提供接口供上層應用構建倒排索引、向量索引(用于語義搜索)等。將索引與原始數據分離但關聯存儲,是提升查詢性能的常見做法。智能化的數據接入服務應能自動完成文本的初步解析、元數據提取和索引構建。
二、關鍵服務組件
一個完整的存儲支持服務體系,通常由以下關鍵組件協同構成:
- 分布式文件/對象存儲層:作為數據的最終承載層,提供高可靠、高可用的基礎存儲能力。對象存儲因其平坦的命名空間和優異的擴展性,已成為文本大數據的主流存儲方案。
- 數據接入與總線服務:提供標準化的API(如RESTful API、Kafka接口)來接收來自各種源頭(FTP、日志采集器、應用直接寫入)的文本數據流。該服務需具備緩沖、流量控制、格式驗證和初步路由能力。
- 元數據管理與目錄服務:作為存儲系統的“大腦”,集中管理所有數據的元信息,提供數據發現、血緣追蹤、權限映射和策略執行(如生命周期管理、加密)功能。
- 索引與查詢加速服務:獨立或集成部署的索引引擎(如Elasticsearch, OpenSearch),專門處理文本的全文檢索、聚合分析請求。存儲系統需與其深度集成,確保數據同步的一致性。
- 數據安全與治理服務:貫穿始終的安全層,提供靜態加密、傳輸加密、細粒度訪問控制(基于角色或屬性)、審計日志以及合規性數據保留/刪除策略。
- 監控與運維支持服務:對存儲集群的健康狀態、性能指標(IOPS、吞吐量、延遲)、容量使用率進行全方位監控,并提供自動化運維工具,如故障自愈、均衡調度、容量預測告警等。
三、技術選型考量與挑戰
在設計實踐中,技術選型需綜合權衡:
- 規模與性能:數據量級(PB/EB級)和并發訪問需求決定了是采用HDFS(適合大文件、批處理)還是對象存儲(適合海量小文件、高并發)。
- 生態集成:存儲系統是否能與主流的大數據處理框架(如Spark、Flink)、分析工具及云服務無縫集成,減少數據搬遷成本。
- 成本控制:總擁有成本(TCO)包括硬件/云資源成本、運維人力成本和能源消耗。分層存儲和壓縮/去重技術是降低成本的關鍵。
- 語義化處理支持:隨著NLP技術的發展,存儲層是否能為 embedding 向量存儲、大語言模型(LLM)的微調數據管理提供原生支持,正成為一個新的考量點。
面臨的挑戰主要包括:如何設計高效的壓縮算法以降低海量文本的存儲開銷;如何在保障查詢性能的實現極致的存儲成本優化;以及如何構建統一的服務接口,屏蔽底層存儲的復雜性,為上層多樣化的應用提供一致、便捷的數據訪問體驗。
四、結論
文本大數據的存儲支持服務設計,是一個以數據為中心、以服務為導向的架構命題。它不再僅僅是提供存儲空間,更是要提供一個涵蓋數據攝入、組織、管理、保護和供應的綜合性平臺。成功的核心在于深刻理解業務的數據訪問模式和價值需求,從而設計出分層清晰、彈性伸縮、智能管理且安全可靠的存儲服務體系。只有這樣,才能讓文本數據這座“礦山”的挖掘工作變得高效、經濟且可持續,真正賦能于智能搜索、輿情分析、風險控制、商業洞察等高級應用,釋放文本大數據的全部潛能。